Sophia Bano
|
Assistant Professor in Robotics and Artificial Intelligence UCL East Robotics and Wellcome/EPSRC Centre for Interventional and Surgical Sciences Department of Computer Science University College London Email: sophia.bano-at-ucl.ac.uk |

|
Spotlights
Biography
I am an Assistant Professor in Robotics and Artificial Intelligence at Department of Computer Science, since November 2022 and I am also part of the Wellcome/EPSRC Centre for Interventional and Surgical Sciences (WEISS), Surgical Robot Vision group, Centre for Artificial Intelligence and UCL Robotics Institute at University College London (UCL). Previously, I worked as a Senior Research Fellow at WEISS where I contributed to the GIFT-Surg (Wellcome/EPSRC Guided Instrumentation for Fetal Therapy and Surgery) project.
My research interests developing computer vision and AI techniques for context awareness, machine consciousness and navigation in minimally invasive and robot-assisted surgery. Particularly, I am interested in context understanding in endoscopic procedures, surgical workflow analysis, field-of-view expansion, 3D reconstruction, perception and navigation for surgical robotics.
I am the Principal Investigator on the UKRI EPSRC AI-enabled Decision Support in Pituitary Surgery project (2023-2025). During my previous roles at UCL, I was one of the leading researchers on the Wellcome/EPSRC Guided Instrumentation for Fetal Therapy and Surgery (GIFT-Surg) project (2014 - 2022) and named researcher on the EPSRC Context-Aware Augmented Reality for Endonasal Surgery (CARES) project (2022 - 2025).
I received the BEng in Mechatronics Engineering and MSc in Electrical Engineering from the National University of Sciences and Technology (NUST), Pakistan. In 2009, I was awarded an Erasmus Mundus Scholarship for the MSc in Computer Vision and Robotics (VIBOT) programme by Heriot-Watt University (UK), University of Girona (Spain) and University of Burgundy (France). This was followed by an internship at Imperial College London (UK) where I contributed to the ERC Soft Tissue Intervention Neurosurgical Guide (STING) project. In 2016, I received a joint PhD from Queen Mary University of London (UK) and Technical University of Catalonia (Spain), funded by an Erasmus Mundus Fellowship. Before joining UCL-WEISS in 2018, I worked as a post-doctoral researcher at the University of Dundee where I contributed to the EPSRC Augmenting Communication using Environmental data to drive Language Prediction (ACE-LP) project.
Areas of Interest
Computer Vision, Surgical Vision, Surgical Data Science, Medical Imaging, Geometric Understanding, Image Registration, Surgical Robotics, Computer-assisted Intervention, Computer-assisted Diagnosis.
Research Highlights
News
- [08/2023] [EPSRC] Awarded UKRI EPSRC funding to develop AI models for decision support in pituitary surgery.
- [06/2023] [MICCAI2023] Co-organising EndoVis2023 PitVis: Workflow recognition in endoscopic pituitary surgery. Click HERE for more details and registration.
- [06/2023] [IPCAI2023] Session chair at the The 14th International Conference on Information Processing in Computer-Assisted Interventions (IPCAI'23) held from June 20th to 21st in Munich, Germany. Click HERE for complete program.
- [11/2022] [2022 UCL Robotics] Started as an Assistant Professor in Robotics and AI at UCL.
- [09/2022] [2022 Hamyln Winter School] Guest lecture on 'Context-aware Surgical Guidance for Next-generation Interventions' at the 2022 Hamlyn Winter School on Surgical Imaging and Vision organised at Imperial College London, UK.
- [09/2022] [MICCAI2022] Session chair for the Surgical Data Science session at the 25th International Conference on Medical Image Computing and Computer Assisted Intervention held from September 18th to 22nd 2022 in Singapore. Click HERE for complete program.
- [06/2022] [HSMR2022] Invited talk on 'Artificial Intelligence-assisted Surgery for Next Generation Intervention' at the workshop on 'Recent Advances in Autonomous Surgery: emerging AI technologies towards machine consciousness and robotic awareness in the surgical field' organised at the 14th Hamlyn Symposium on Medical Robotics (HSMR2022), Imperial College London (UK).
- [06/2022] [HSMR2022] Our team's entry ''Towards soft robot assisted needle insertion in intratympanic steroid injections' won the Best Innovation Award at the 2022 Surgical Robot Challege organised at the 14th Hamlyn Symposium on Medical Robotics (HSMR2022), Imperial College London (UK).
- [05/2022] [MICCAI2022] Co-organising the 2nd Edition of Women in MICCAI (WiM) Inspirational Leadership legacy (WILL). Click HERE for more details.
- [04/2022] [IPCAI2022] Two papers accepted at IPCAI2022.
- [04/2022] [MICCAI2021] Co-organising EndoVis2022 SimCol-to-3D 2022 - 3D Reconstruction during Colonoscopy. Click HERE for more details and registration.
- [04/2021] [MICCAI2022] Co-organising aFfordable healthcare and AI for Resource diverse global health (FAIR). Click HERE for CfP details.
- [02/2022] [MICCAI2022] Serving on the organisation committee for Endoscopic Vision Challenges ()MICCAI-EndoVis2022).
- [01/2022] [MICCAI2022] Serving as an Area Chair at MICCAI2022.
- [11/2021] [MICCAI2022] Serving as the Tutorials Co-chair for MICCAI2022.
- [11/2021] Invited keynote on Artificial Intelligence in Minimally Invasive Surgery at "The 7 Future Directions of Artificial Intelligence" international workshop, Sousse (Tunisia). Click here to watch the recording of my talk.
- [09/2021] [IPCAI2022] Serving as an Area Chair at IPCAI2022.
- [05/2021] [MICCAI2021] Co-organising Women in MICCAI (WiM) Inspirational Leadership legacy (WILL). Click HERE for more details.
- [04/2021] [MICCAI2021] Co-organising EndoVis2021 FetReg Challenge on Placental Vessel Segmentation and Registration in Fetoscopy. Click HERE for more details and registration.
- [04/2021] [MICCAI2021] Co-organising aFfordable healthcare and AI for Resource diverse global health (FAIR). Click HERE for CfP details.
- [01/2021] [MICCAI2021] Serving as an Area Chair at MICCAI2021.
- [01/2021] [ICPR2020] Our work Hybrid Loss with Network Trimming for Disease Recognition in Gastrointestinal Endoscopy was top ranked in the EndoTect Challenge organised at ICPR 2020.
-
[10/2020] [MICCAI2020] Our paper on Deep Learning-based Fetoscopic Mosaicking for Field-of-View Expansion won the
IJCARS - MICCAI2019 Best Paper Award . Video presentation is available HERE. Checkout the MICCAI society website and these tweets for more details. - [10/2020] [MICCAI2020] Daily Whiteboard featured our work on Computer-Assisted Fetoscopy Surgery. Check out these tweets about my work.
- [10/2020] [MICCAI2020] Won the 2nd prize in the MICCAI2020 EndoVis Cataracts Segmentation Challenge. Check out my tweet on this.
- [10/2020] [MICCAI2020] Oral presentation on Placental Vessel Segmentation for Fetoscopic Video Mosaicking.
- [08/2020] Paper on Field-of-View Expanision in Fetoscopy published in IJCARS.
- [08/2020] Invited talk on Mosaicking using Deep Leaning for Fetoscopic Surgery at WEISS mini-symposium on Artificial Intelligence in Surgery. Click here to watch the recording of my talk.
- [07/2020] In vivo Fetocopic Videos Dataset with vessel annotations has been released. Click here for details.
- [06/2020] Paper on Placental Vessel Segmentation for Fetoscopic Video Mosaicking accepted at MICCAI 2020.
- [04/2020] Paper on Occlusion Detection in Fetoscopic Surgery accepted at IPCAI 2020 and published in IJCARS.
- [04/2020] Paper on Anatomical Site Classification in Upper GI Endoscopy accepted at IPCAI 2020 and published in IJCARS.
- [09/2020] Co-organise Endoscopic Computer Vision Challenge and workshop at ISBI 2020.
- [06/2019] Paper on Mosaicking using Deep Learning in Fetoscopic Surgery accepted at MICCAI 2019.
- [10/2018] Sophia's picks published in Computer Vision News during MICCAI 2018.
- [09/2018] Co-organise Vision for Interaction and Behaviour Understanding workshop at BMVC 2018.
- [08/2018] Paper on Deep learning for Cross-Modality MR Image Inference accepted at MICCAI 2019 PRIME workshop.
- [06/2018] Joined Surgical Robot Vision Group in WEISS at University College London (UCL), UK.
- [06/2018] Multimodal Focused Interaction Dataset has been released. Click here for details.
- [06/2018] Paper on Multimodal Egocentric Analysis of Focused Interactions accepted to IEEE Access.
- [11/2017] Talk on Egocentric Focused Interaction Classification at BMVA meeting on Human Activity Monitoring & Recognition.
- [08/2017] Paper on Focused Interaction Detection in Egocentric Video accepted at ICCV 2017 EPIC worshop.
- [09/2016] Interview appeared in Computer Vision News Special Section on Women in Computer Vision.
- [09/2016] Attended International Computer Vision Summer School in Sicily, Italy.
- [04/2016] Joined Computer Vision and Image group at University of Dundee (UoD), UK.
- [01/2016] Delievered Public Presentation of PhD Thesis, in line with the Erasmus Mundus Joint Doctorate in Interactive and Cognitive Environments regulations, at Queen Mary University of London (QMUL), UK
- [10/2015] Multimodal User-Generated Videos Dataset has been released. Click here for details.
- [10/2015] Paper on Gyro-based Camera Motion Detection in UGVs accepted at ACM Multimedia Conference 2015.
- [10/2015] Successfully defended PhD thesis at Queen Mary University of London for the award of Erasmus Mundus Joint Doctorate in Interactive and Cognitive Environments.
Selected Publications
For complete list of publications, CLICK HERE.
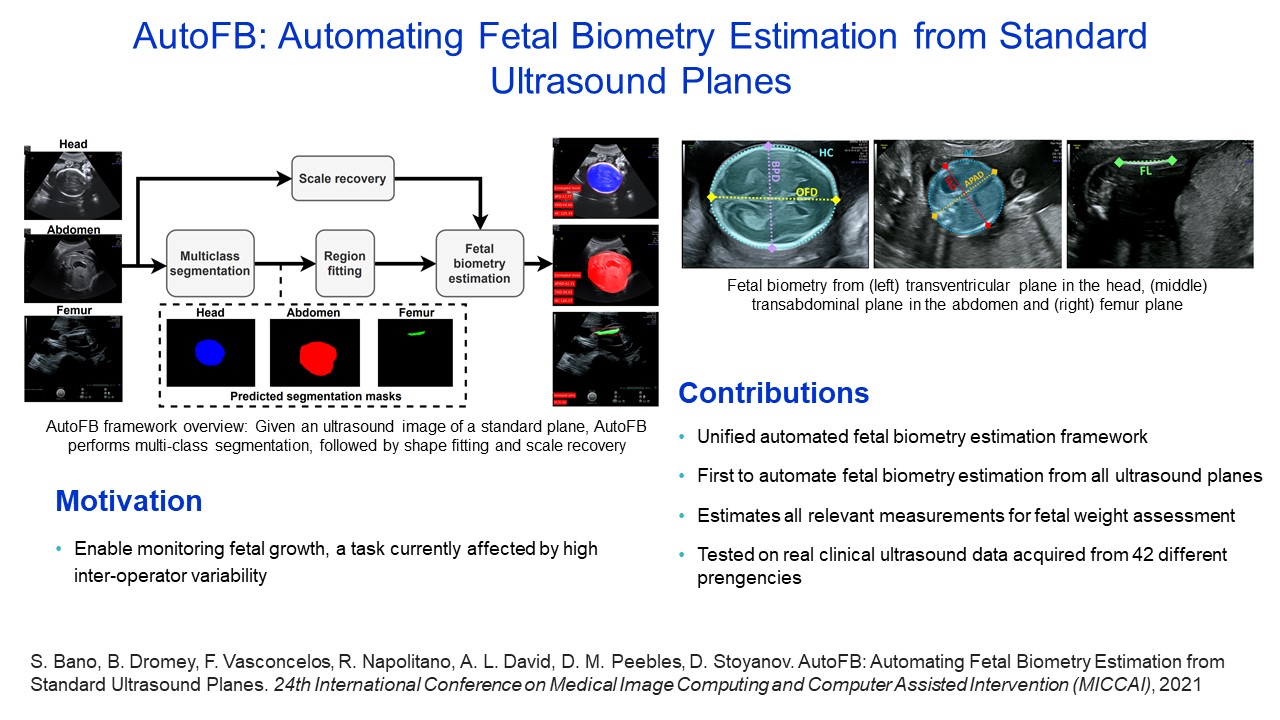 |
AutoFB: Automating Fetal Biometry Estimation from Standard Ultrasound Planes |
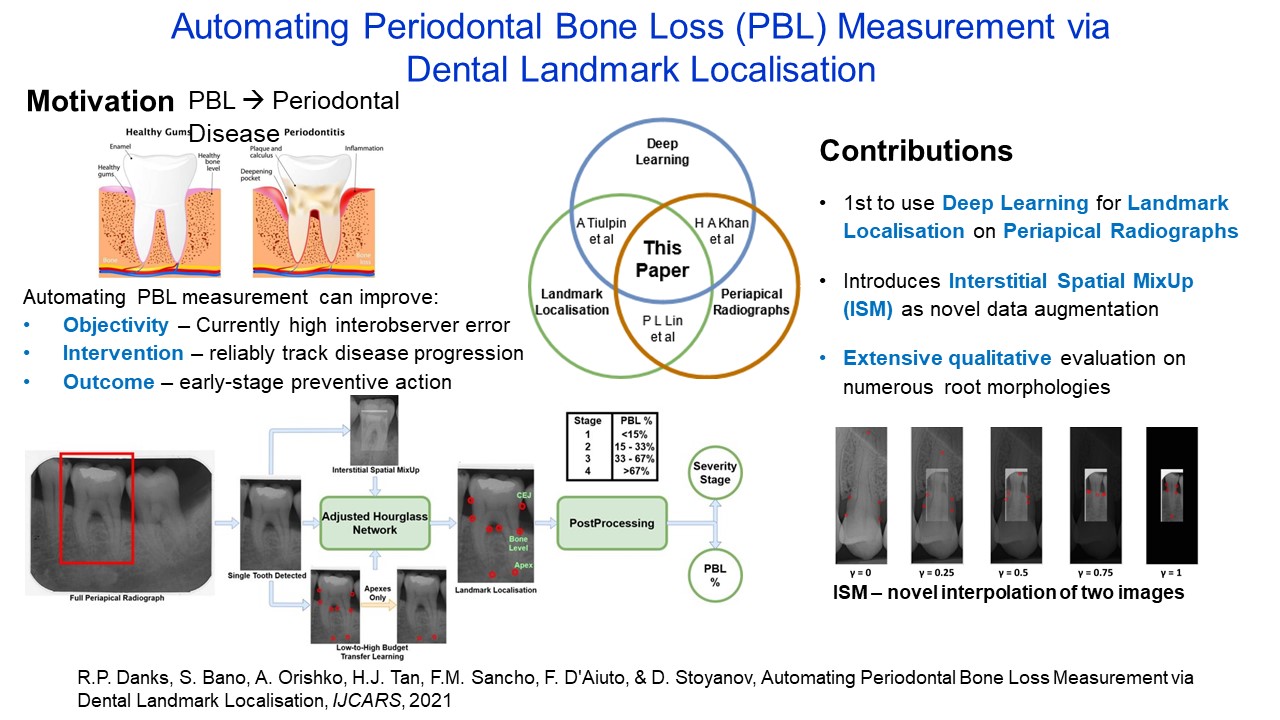 |
Automating Periodontal Bone Loss Measurement via Dental Landmark Localisation |
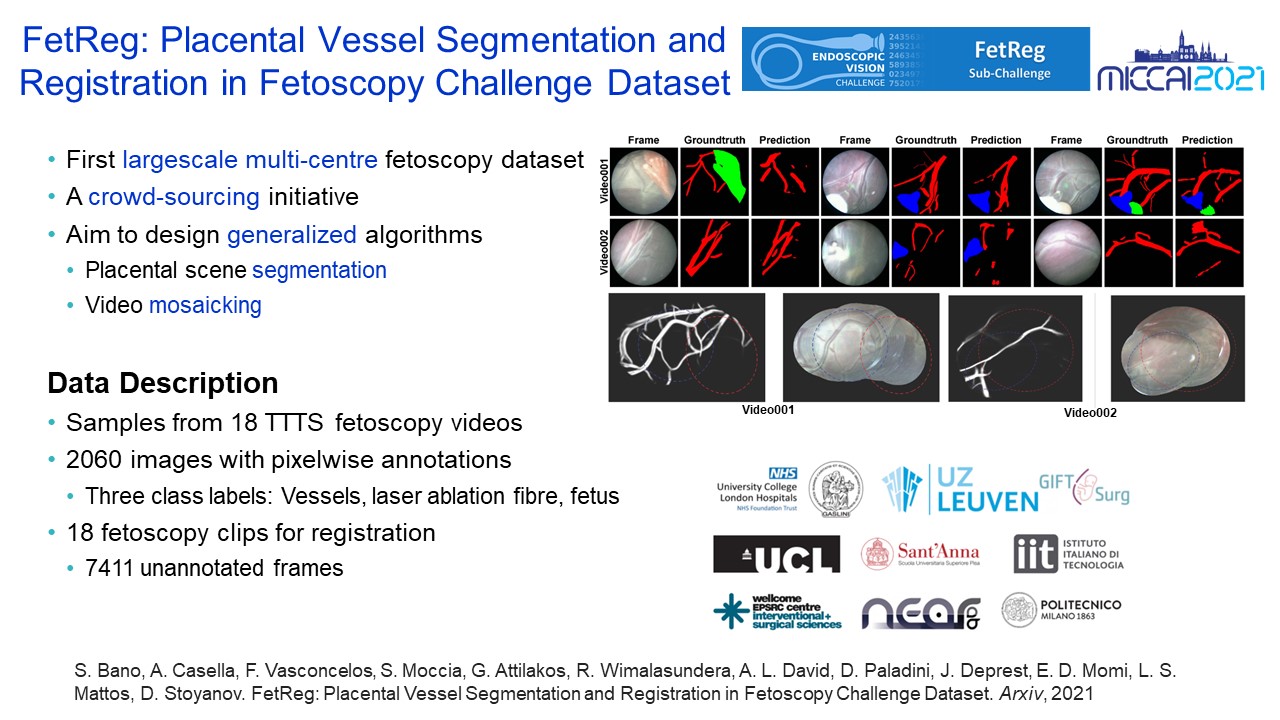 |
FetReg: Placental Vessel Segmentation and Registration in Fetoscopy Challenge Dataset |
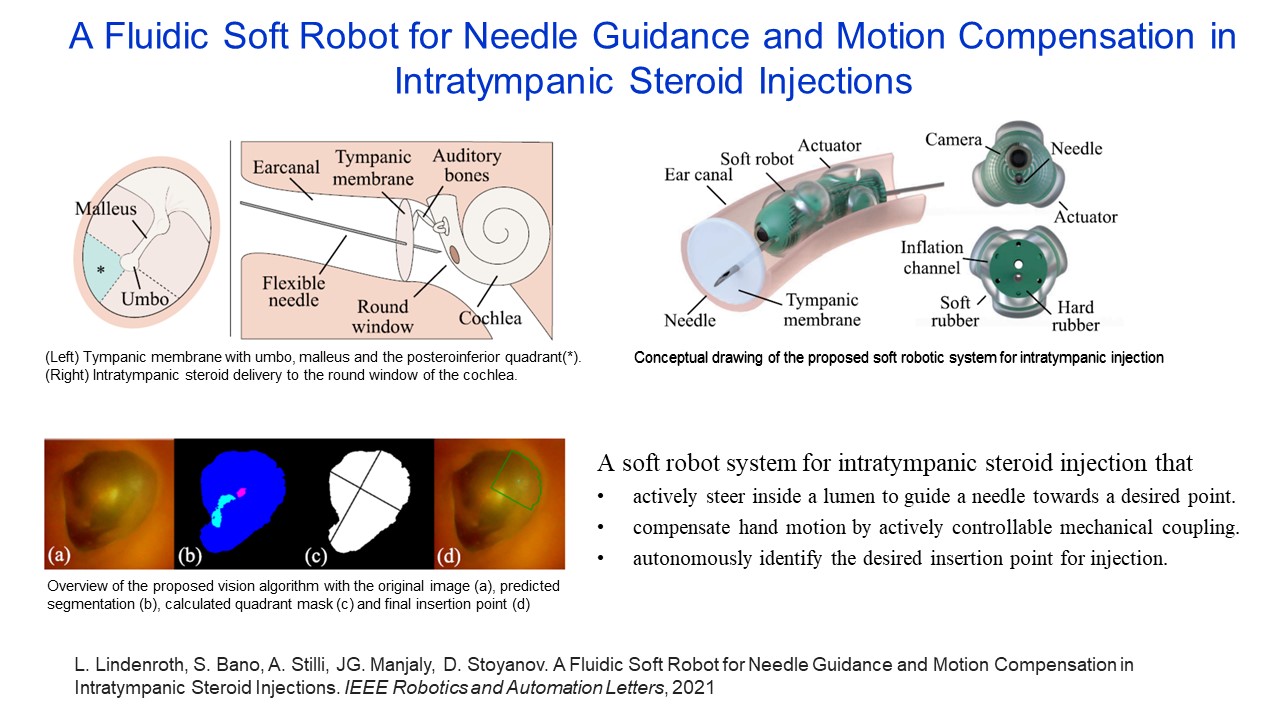 |
A Fluidic Soft Robot for Needle Guidance and Motion Compensation in Intratympanic Steroid Injections |
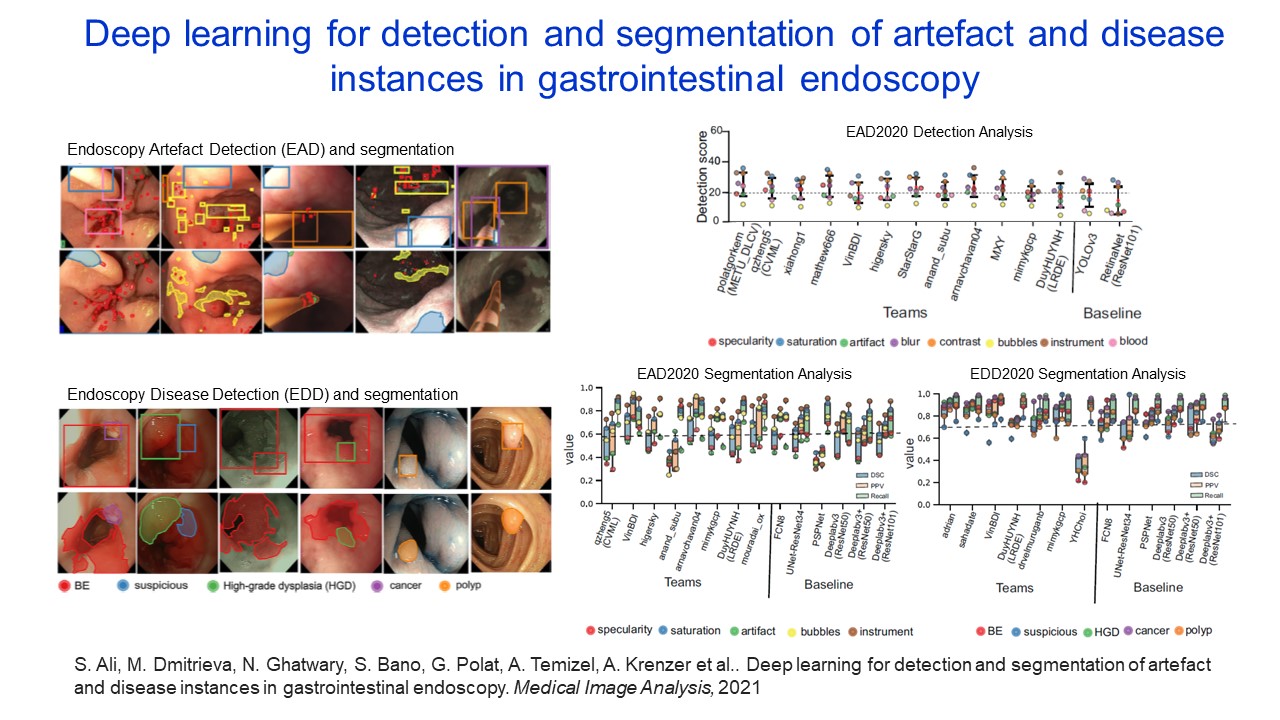 |
Deep learning for detection and segmentation of artefact and disease instances in gastrointestinal endoscopy |

|
Deep Learning-based Fetoscopic Mosaicking for Field-of-View Expansion |
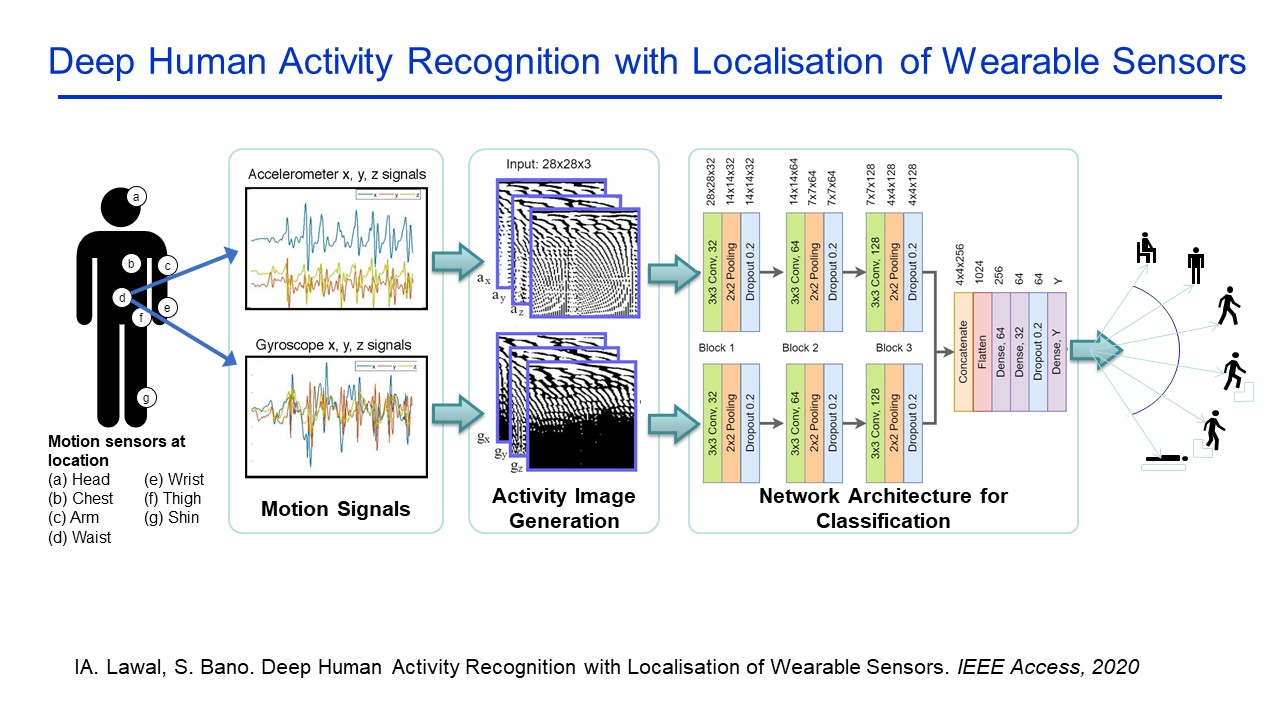 |
Deep Human Activity Recognition with Localisation of Wearable Sensors |
|
Deep Placental Vessel Segmentation for Fetoscopic Mosaicking |
|
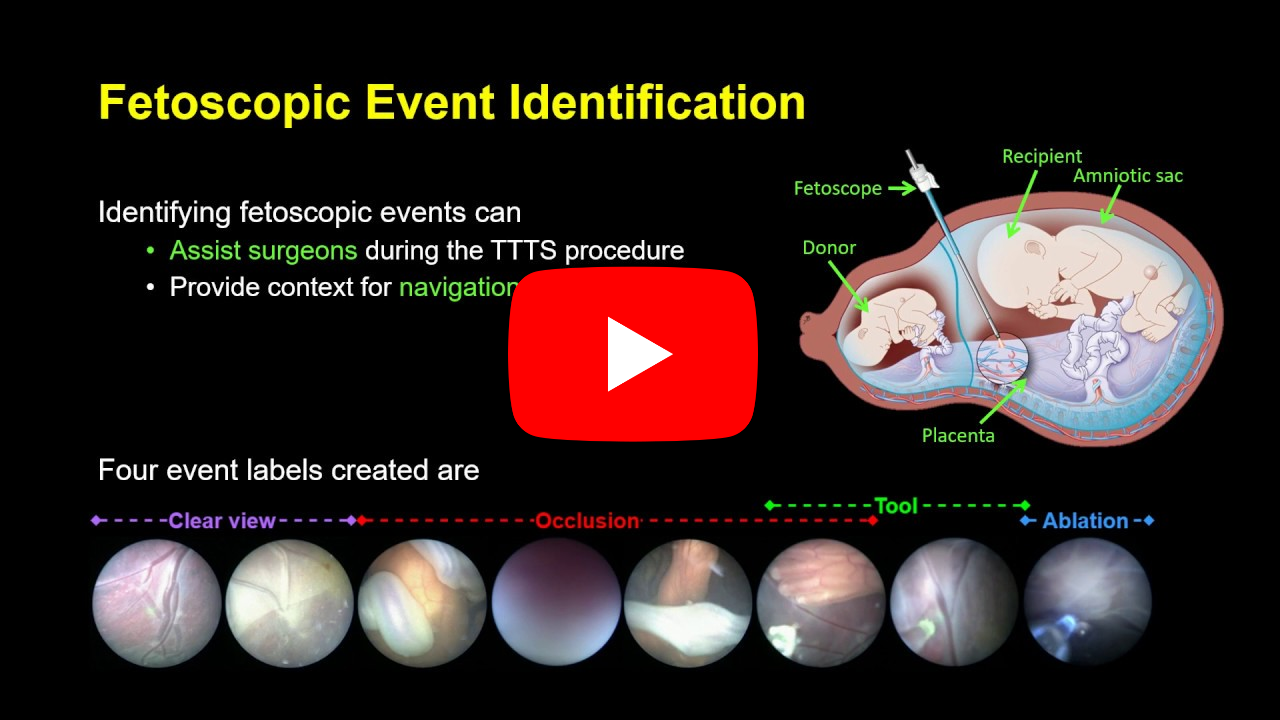
FetNet: A Recurrent Convolutional Network for Occlusion Identification in Fetoscopic Videos |
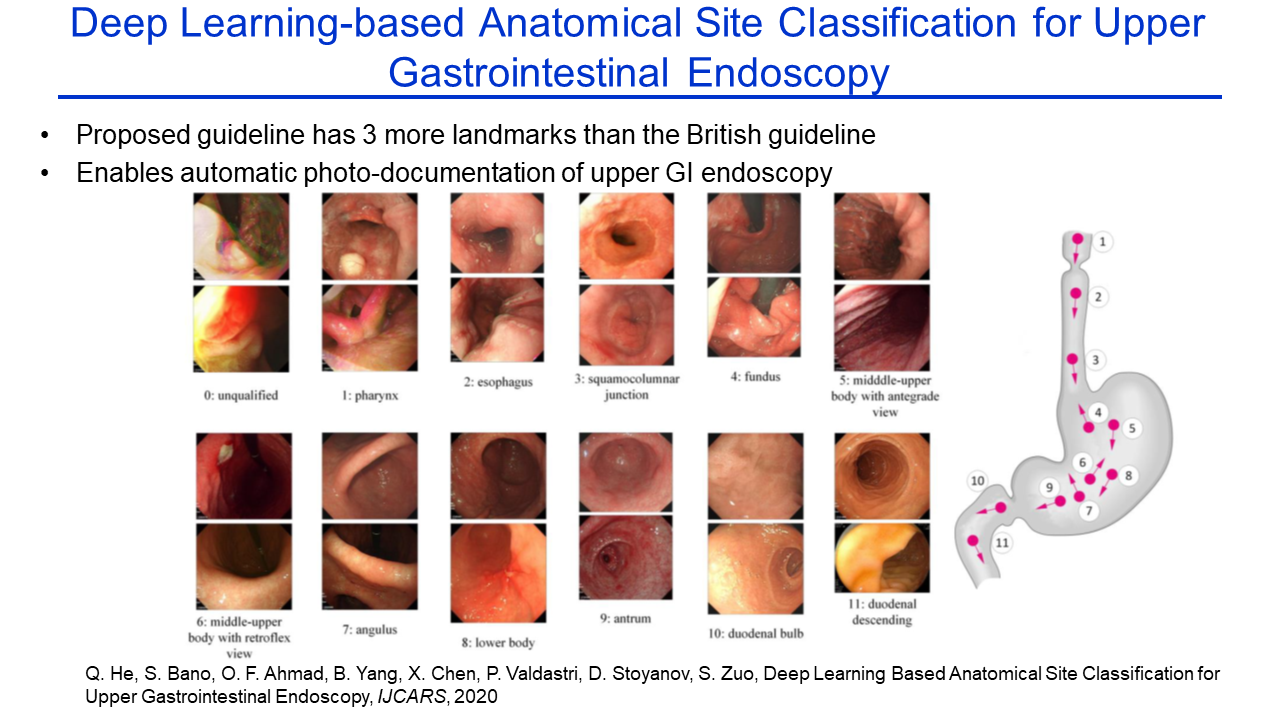 |
Deep Learning Based Anatomical Site Classification for Upper Gastrointestinal Endoscopy |
|
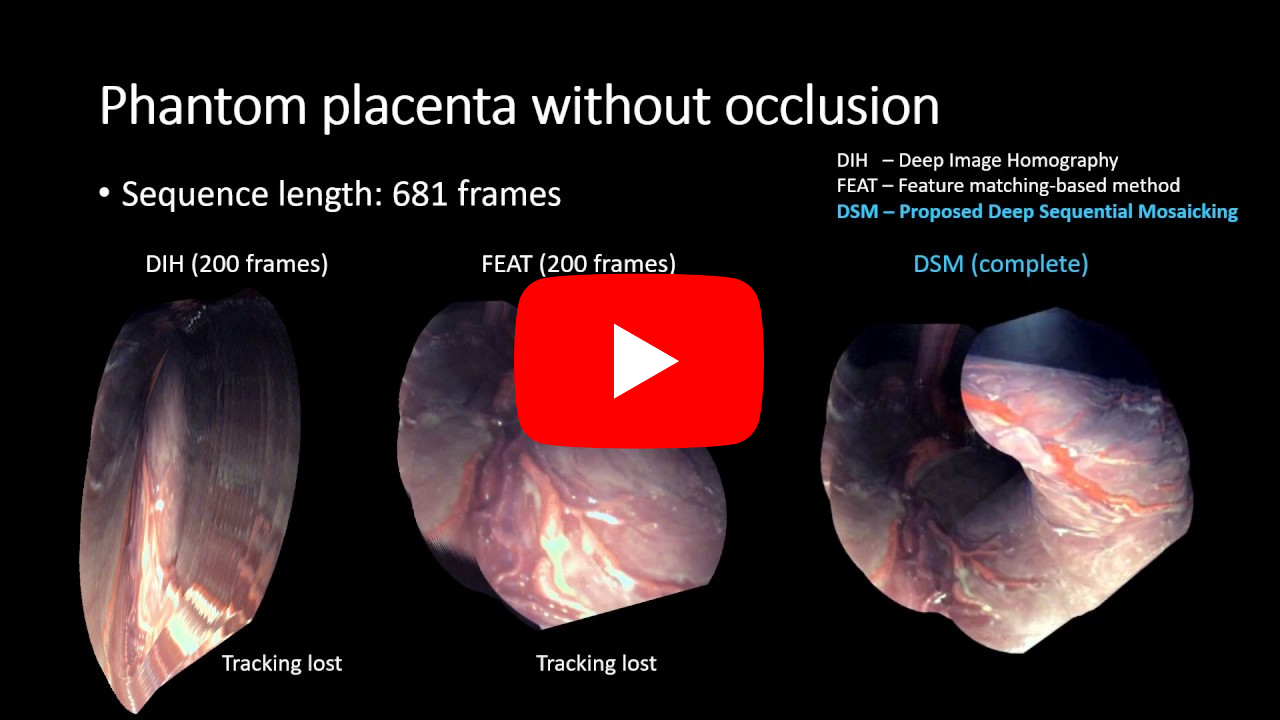
Deep Sequential Mosaicking of Fetoscopic Videos |
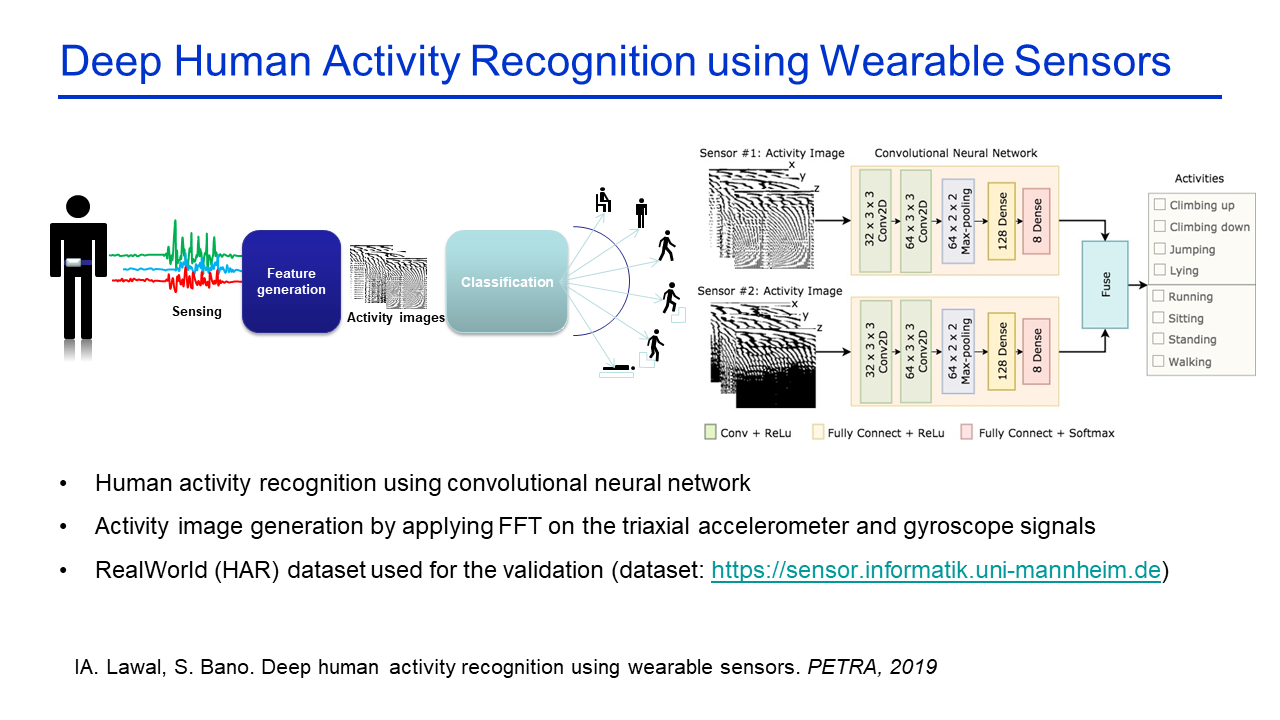 |
Deep Human Activity Recognition using Wearable Sensors |
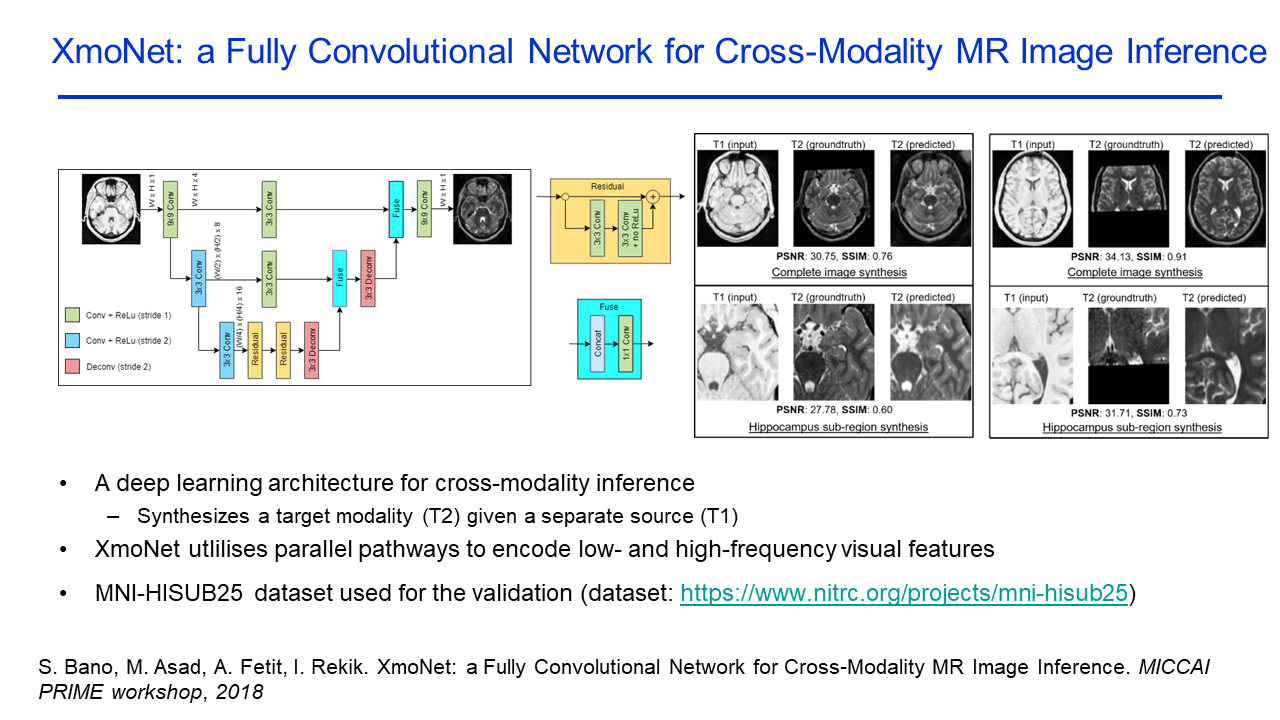 |
XmoNet: A Fully Convolutional Network for Cross-Modality MR Image Inference |
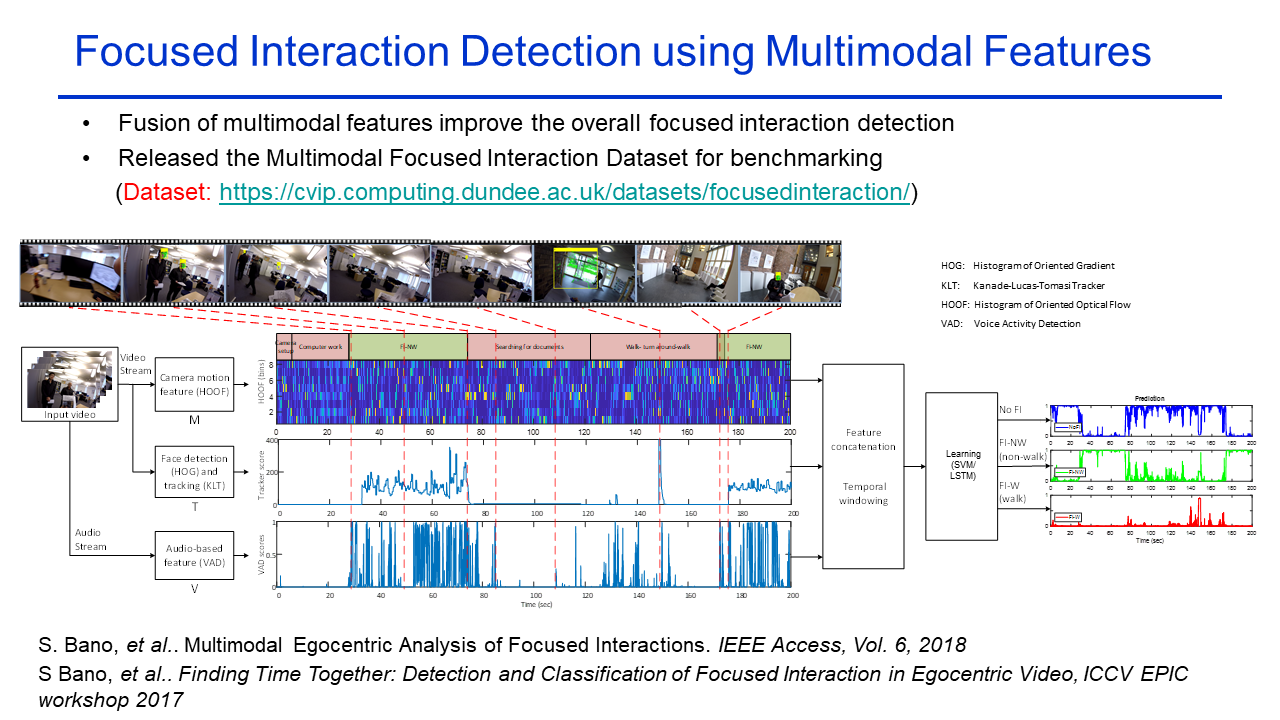 |
Multimodal Egocentric Analysis of Focused Interactions Finding Time Together: Detection and Classification of Focused Interaction in Egocentric Video |
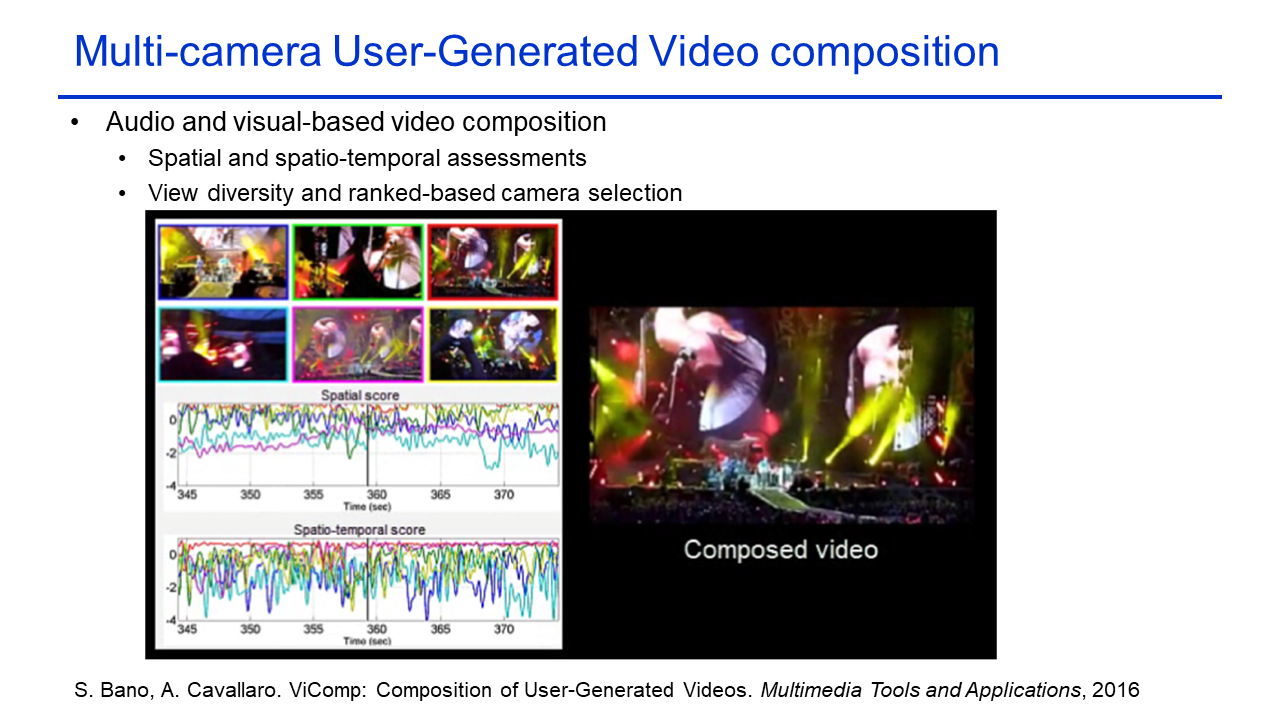 |
ViComp: Composition of User-Generated Videos |
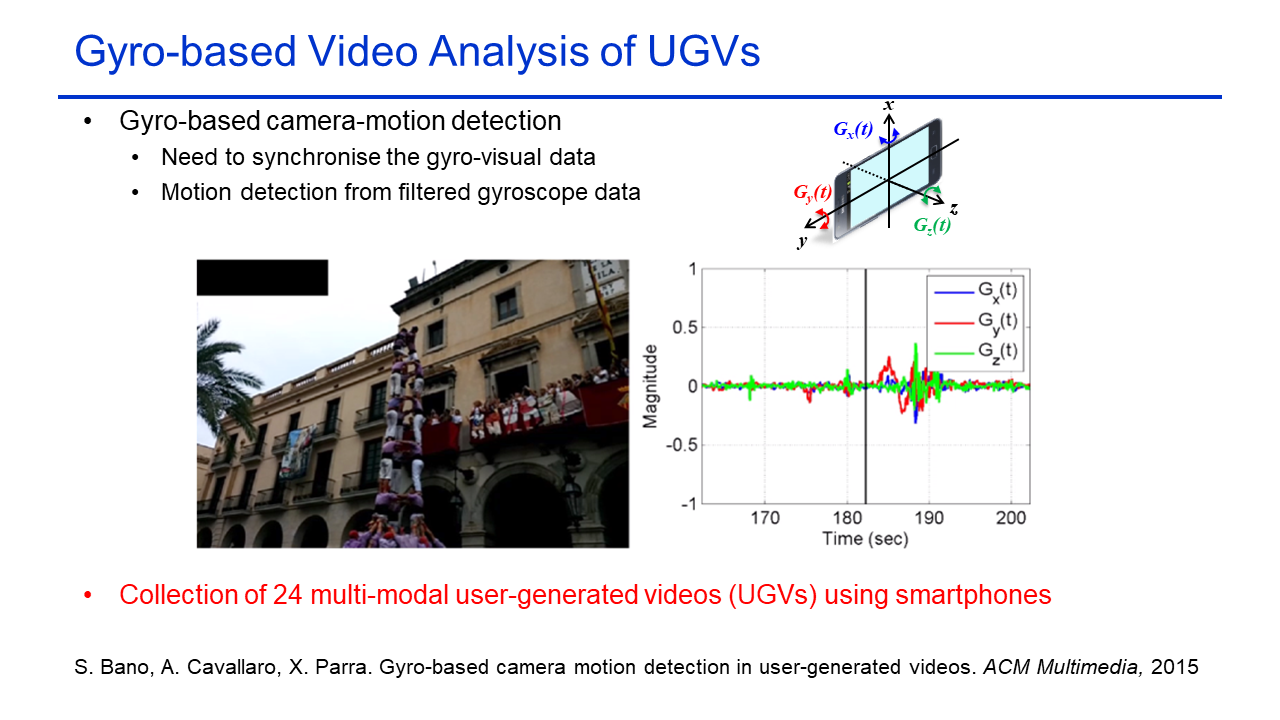 |
Gyro-based Camera Motion Detection in User-Generated Videos |
 |
Discovery and Organization of Multi-Camera User-Generated Videos of the Same Event |
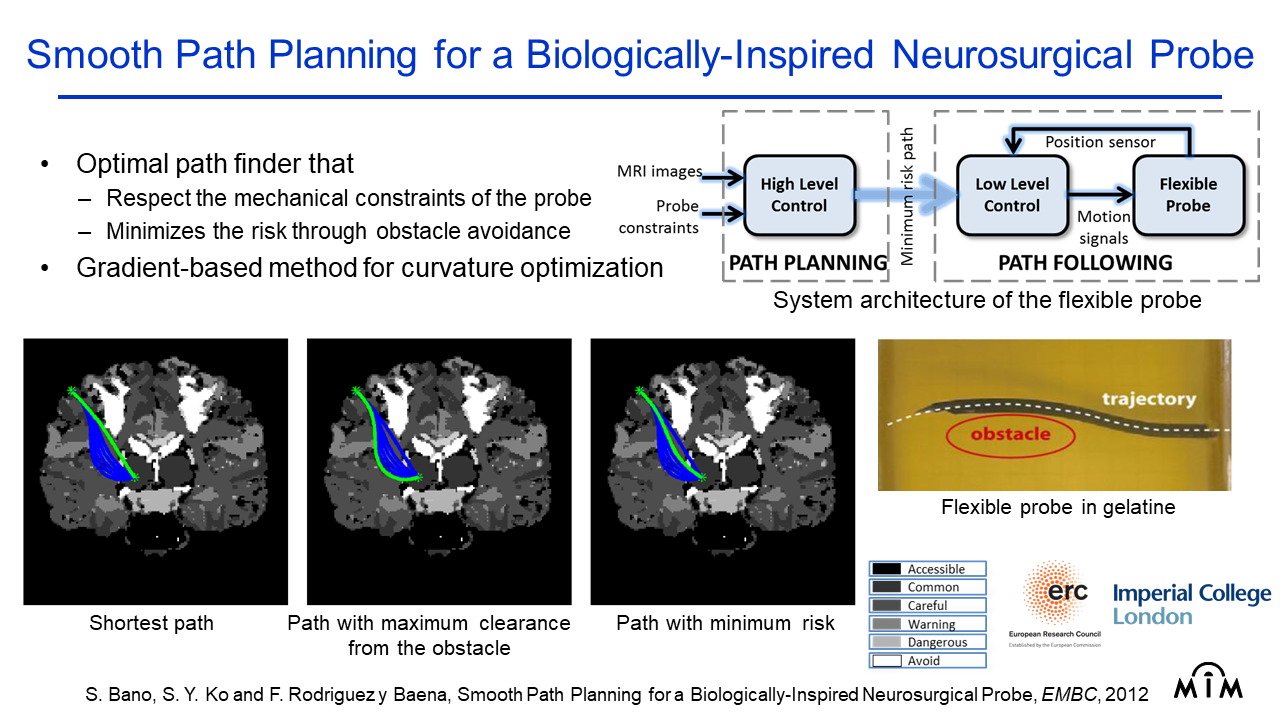 |
Smooth Path Planning for a Biologically-Inspired Neurosurgical Probe |
For complete list of publications, CLICK HERE.
Datasets
The fetoscopy placenta dataset is associated with our MICCAI2020 publication titled “Deep Placental Vessel Segmentation for Fetoscopic Mosaicking” (insert arxiv link). The dataset contains 483 frames with ground-truth vessel segmentation annotations taken from six different in vivo fetoscopic procedure videos. The dataset also includes six unannotated in vivo continuous fetoscopic video clips (950 frames) with predicted vessel segmentation maps obtained from the leave-one-out cross validation of our method.
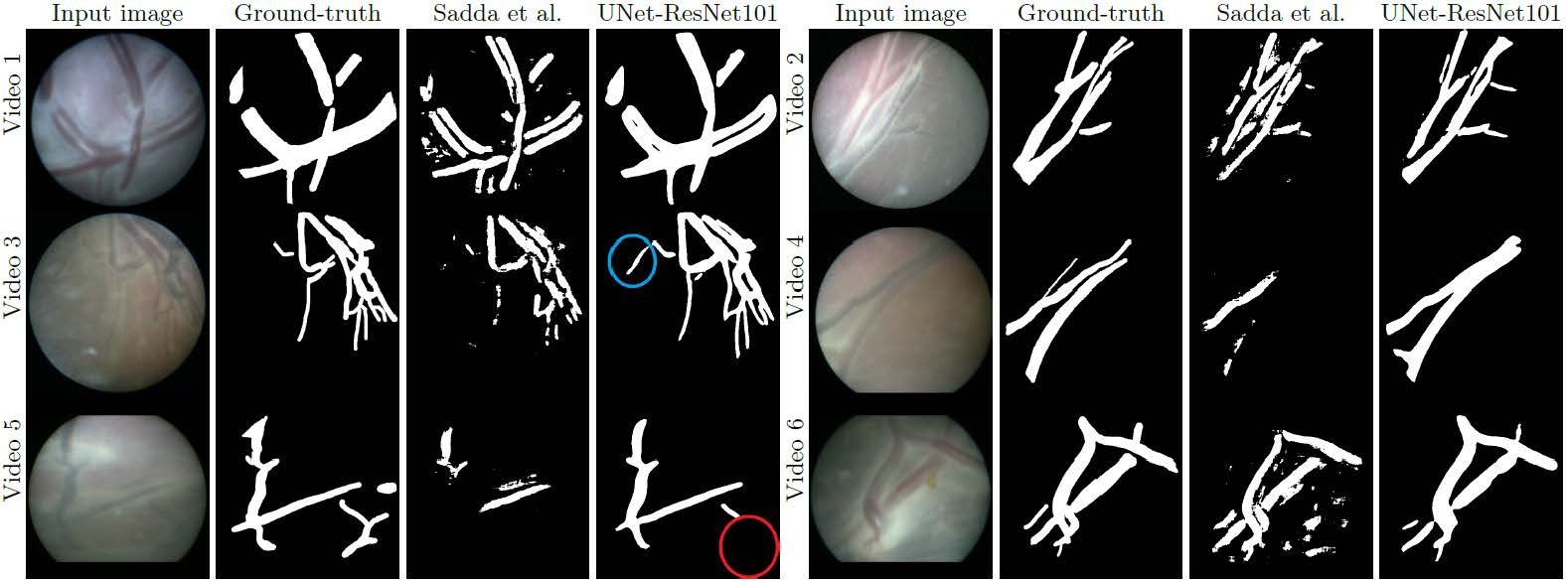
Visit Fetoscopy Placenta Dataset website to access the data.
Reference
Deep Placental Vessel Segmentation for Fetoscopic Mosaicking
Multimodal Egocentric Analysis of Focused Interactions
Finding Time Together: Detection and Classification of Focused Interaction in Egocentric Video
The Focused Interaction Dataset} contains 19 egocentric continuous videos (378 mins) captured, at high resolution (1080p) and at a frame rate of 25 fps, using a shoulder-mounted GoPro Hero4 camera and a smartphone (for inertial and GPS data), at 18 different locations and with 16 different conversational partners. This dataset is annotated into periods of no focused interaction, focused interaction (non-walk) and focused interaction (walk). This dataset is captured at several indoor and outdoor locations at different times of the day and night, and in different environmental conditions.
Visit Focused Interaction Dataset website to access the data.
References
Gyro-based Camera Motion Detection in User-Generated Videos
The multimodal dataset contains 24 user-generated videos (70 mins) captured using handheld mobile phones in high brightness and low brightness scenarios (e.g. day and night-time). The video (audio and visual) along with the inertial sensor (accelerometer, gyroscope, magnetometer) data is provided for each video. These recordings are captured using single camera at distinct timings and locations, changing lights and varying camera motions. Each captured video was manually annotated to get labels for camera motions (pan,tilt, shake) at each second. The ground-truth labels are included in the dataset.
Visit UGV Dataset website to access the data.
Reference
Services
Organising roles:
- Lead organiser of the Women in MICCAI Inspirational Leadership Legacy (WiM-WILL2021) at the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Strasbourg (Virtual), France, 2021
- Lead organiser of the Placental Vessel Segmentation and Registration in Fetoscopy (FetReg2021) at the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Strasbourg (Virtual), France, 2021
- Co-organised the 1st workshop on Affordable Healthcare and AI for Resource Diverse Global Health (FAIR2021) at the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Strasbourg (Virtual), France, 2021
- Co-organised the 6th Endoscopic Vision (EndoVis2021) Challenges in conjuction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Strasbourg (Virtual), France, 2021
- Co-organised the 2nd Endoscopy Computer Vision (EndoCV2020) Challenge and Workshop in conjuction with the 17th IEEE International Symposium on Biomedical Imaging (ISBI), Iowa (Virtual Conference), USA, 2020
- Co-organised the Vision for Interaction and Behaviour undErstanding (VIBE2018) workshop in conjuction with the 29th British Machine Vision Conference (BMVC), Newcastle, UK, 2018
Peer Review roles:
- Area chair for 25th International Conference on Medical Image Computing and Computer Assisted Intervention (2022)
- Tutorials co-chair for 25th International Conference on Medical Image Computing and Computer Assisted Intervention (2022)
- Area chair for 13th International Conference on Information Processing in Computer-Assisted Interventions (IPCAI) (2022)
- Area chair for 17th International Conference on Computer Vision Theory and Applications (2022)
- Area and Session chair for 24th International Conference on Medical Image Computing and Computer Assisted Intervention (2021)
- Area chair for 16th International Conference on Computer Vision Theory and Applications (2021)
- Area chair for 15th International Conference on Computer Vision Theory and Applications (2020)
- Grant proposal reviewer for Health Research Council of New Zealand (2019)
- Program committee member for the Women in Computer Vision Workshop at CVPR (201821)
Journal Reviewers:
- IEEE Transactions on Medical Imaging
- IEEE Journal of Biomedical and Health Informatics
- IEEE Transactions on Biomedical Engineering
- IEEE Transactions on Pattern Analysis and Machine Intelligence
- IEEE Transactions on Robotics
- IEEE Transactions on Medical Robotics and Bionics
- IEEE Robotics and Automation Letters
- Elsevier Pattern Recognition Letters
- IEEE Transactions on Multimedia
- IET Computer Vision
- Springer The Visual Computer
Conference Reviewers:
- Medical Image Computing and Computer Assisted Intervention (MICCAI 2020)
- International Symposium on Intelligent Computing Systems (ISICS 2020)
- Predictive Intelligence in Medicine (PRIME-MICCAI 2019)
- Medical Image Computing and Computer Assisted Intervention (MICCAI 2019)
- International Conference on COmputer Vision (ICCV 2019)
- Medical Imaging with Deep Learning (MIDL 2019)
- Assistive Computer Vision and Robotics (ECCV-ACVR 2018)
- Women in Computer Vision (CVPR-WiCV 2018)
- ACM Multimedia (ACMMM 2016)